










AMD erklärt die Wirtschaftlichkeit hinter Chiplets für GPUs
Ein Beispiel für ein MCM wäre ein mobiler Intel Core Prozessor, bei dem der CPU-Chip und der PCH-Chip ein gemeinsames Substrat haben. Hierher, Die CPU und der PCH sind unabhängige Siliziumteile, die andernfalls in eigenen Paketen vorhanden sein könnten (wie auf der Desktop-Plattform), Sie wurden jedoch auf einem einzigen Substrat gepaart, um den PCB-Fußabdruck zu minimieren, was auf einer mobilen Plattform wertvoll ist. Bei einem Chiplet-basierten Gerät besteht ein Substrat aus mehreren Chips, die ansonsten nicht unabhängig voneinander in ihren eigenen Gehäusen existieren können, ohne dass dies Auswirkungen auf die Bandbreite oder Latenz zwischen den Chips hat. Es handelt sich im Wesentlichen um Komponenten, die auf einem monolithischen Chip vorhanden sein sollten, aber in separate Chips zerfallen, die auf verschiedenen Halbleiter-Foundry-Knoten aufgebaut sind, mit einem rein kostengetriebenen Motiv.
AMDs Umstellung auf Chiplets wird durch steigende Kosten für Halbleiterwafer vorangetrieben, während der Siliziumherstellungsprozess entlang der Transistorgrößenskala voranschreitet. Obwohl AMD zu einem Fabless-Unternehmen wurde 13 years ago, Es gab eine nette Vereinbarung mit Globalfoundries, die ehemalige AMD-Foundry-Abteilung, die sie ausgegliedert hat. Das Unternehmen bezog bis dahin weiterhin Prozessoren von Globalfoundries 14 FinFET-Knoten der Klasse nm-12 nm, und obwohl Globalfoundries ursprünglich geplant hatte, einen Sub-10-nm-Knoten herzustellen, der mit TSMC konkurrenzfähig war 7 nm und Samsung 8 nm; Diese Pläne scheiterten. AMD unterhielt Beziehungen zu TSMC, aus dem es seine Radeon-GPUs herstellte. Da hatte TSMC das Beste 7 Knoten der nm-Klasse und die Fähigkeit, die Produktion nach oben zu skalieren; Das Unternehmen machte seine größte Wette, Bauprozessoren auf 7 nm.
AMD ist kaum der einzige Kunde von TSMC, und das Unternehmen erkannte bald, dass es keine monolithischen CPUs mit hoher Kernzahl herstellen konnte 7 nm stirbt; Es konnte auch nicht das tun, was es mit EPYC getan hat “Neapel,” was im Grunde genommen der Fall war “4P auf einem Stock” MCMs, mit verschwendetem Chipplatz durch redundante Komponenten. Dadurch wurde der Prozessor zerstört. Die Komponenten, die am meisten von der Schrumpfung profitieren könnten 7 nm; die CPU-Kerne, würde auf winzigen Würfeln gebaut werden, die enthalten 8 Jeweils CPU-Kerne, was das Unternehmen als CPU-Komplex-Chips bezeichnen würde (CCDs). Je kleiner der Würfel, desto höher ist die Ausbeute pro Wafer, und so entschied das Unternehmen, dass a 80 mm² großes Stück Silizium mit 8 CPU-Kerne, würde mit einem separaten Chip sprechen, der alle Komponenten enthält, die auf einem etwas älteren Knoten aufgebaut werden könnten, mit minimalen Auswirkungen auf die gesamten Leistungs-/Wärmeeigenschaften des Produkts. Man würde dies als I/O-Chip bezeichnen. AMD würde mit diesem Ansatz sowohl Client-Ryzen- als auch Server-EPYC-Produkte entwickeln, da die 8-Kern-CCDs beiden Produktlinien gemeinsam waren. Der Client-Desktop-Prozessor verfügt über einen kleineren I/O-Chip, der für die Plattform geeignet ist, was es cIOD nennen würde (Client-E/A-Fehler), während der Serverteil, mit der Möglichkeit, eine größere Anzahl von CCDs anzuschließen, würde als sIOD bezeichnet werden (Server-I/O sterben). AMD bezog weiterhin I/O-Chips von Globalfoundries, auf Ihrer 12 nm Knoten, seit drei Jahren. Mit dem neuesten Ryzen 7000 und EPYC-Prozessoren der 4. Generation basierend auf “Zen 4,” AMD baut die CCDs auf 5 nm EUV-Knoten, während die I/O-Chips auf den weniger fortgeschrittenen basieren 6 nm Knoten.
Schneller Vorlauf, und AMD sah sich mit einem Problem mit seinen Radeon-GPUs konfrontiert. Das Unternehmen verdient mit dem Verkauf diskreter GPUs nicht so viel Geld wie mit CPUs (Client+Server), Daher ist die Notwendigkeit, die Herstellungskosten zu senken, umso größer, ohne die Wettbewerbsfähigkeit gegenüber NVIDIA zu verlieren. Mit der GeForce “Den Fluch erschaffen – PlayStation.Blog,” Generation, NVIDIA setzt weiterhin auf monolithisches Silizium für GPUs, sogar seinen größten bauen “AD102” Chip als klassische monolithische GPU. Dies bietet AMD die Möglichkeit, die Herstellungskosten seiner GPUs zu senken, was es ihm ermöglichen könnte, Preiskämpfe gegen NVIDIA zu führen, in dem Versuch, Marktanteile zu gewinnen. Ein typisches Beispiel ist die relativ aggressive Preisgestaltung, die AMD für die Radeon RX anwendet 7900 XTX, bei $999; und der RX 7900 XT bei $899, Das Unternehmen glaubt, dass sie das Zeug dazu haben, den Kampf gegen NVIDIA aufzunehmen $1,199 RTX 4080 und wahrscheinlich sogar einen Schlagabtausch mit dem $1,599 RTX 4090 in einigen Best-Case-Szenarien.
Schritt eins, eine High-End-GPU zu zerlegen, ohne ihre Leistung zu beeinträchtigen, Rahmenzeiten, und Leistungs-/Wärmeeigenschaften; besteht darin, die spezifischen Komponenten auf dem Silizium zu identifizieren, die in Chiplets umgewandelt werden könnten, das kann mit einem älteren Foundry-Knoten auskommen. Für einen EPYC-Serverprozessor, sogar mit 9-12 Chiplets, Das Unternehmen muss sich nur mit Hunderten von Signalpfaden befassen, die das Substrat durchqueren, um die Chiplets miteinander zu verbinden. Eine diskrete High-End-GPU ist viel komplexer, und die Größe dieser Inter-Chiplet-Signalpfade geht in die Tausende (im Falle der Älteren “Navi 21” RDNA2-Silizium). Mit dem größeren “DOOM und DOOM II haben gerade ein weiteres kostenloses Add-On erhalten” RDNA3, Diese Zahl wird nur noch höher sein. Das Unternehmen identifizierte die Komponenten, die mindestens ein Drittel der Die-Fläche ausmachten und von der Umstellung nicht spürbar profitieren würden 5 nm EUV – das wären die GDDR6-Speichercontroller, Speicher-PHY, und der Infinity-Cache-Speicher (Der L3-Cache der GPU wird von allen Shader-Engines gemeinsam genutzt).
GPUs mit Speicherschnittstellen, die breiter als 64-Bit sind, verwenden in der Regel mehrere 64-Bit-Speichercontroller, die verschachtelt sind, um eine breitere Speicherschnittstelle zu schaffen (wie 128-Bit, 256-bisschen, 384-bisschen, etc). Dies ist sowohl bei AMD als auch bei NVIDIA der Fall. AMD hat daher entschieden, dass nicht nur die Speichercontroller abgespalten werden, sondern auch jeder Speichercontroller mit einem 64-Bit-Speicherpfad, wäre ein eigener Chiplet, und habe ein 16 MB-Segment der GPUs 96 MB Infinity Cache-Speicher. Dieser Speichercontroller + Das Cache-Chiplet wird als Speicher-Cache-Chip bezeichnet (MCD); während der Rest der GPU mit ihren Hardcore-Logikkomponenten tatsächlich davon profitiert 5 Nanometer EUV, würde in einen größeren zentralisierten Chip integriert werden, der als grafischer Rechenchip bezeichnet wird (GCD). Die “DOOM und DOOM II haben gerade ein weiteres kostenloses Add-On erhalten” Die GPU verfügt über eine 384 Bit breite GDDR6-Speicherschnittstelle, und so gibt es sechs MCDs. Vorausgesetzt, AMD bleibt auch bei seinen kleineren GPUs beim Chiplet-Design, Es kann einfach eine kleinere Anzahl derselben MCDs verwendet werden, um schmalere Speicherschnittstellen zu erreichen, wie 256-Bit (4x MCDs), 192-bisschen (3x MCDs), oder 128-Bit (2x MCDs).
Während die Verbindung zwischen GCD und MCDs immer noch Infinity Fabric ist, AMD musste eine neue Verkabelungstechnologie für die physikalische Schicht entwickeln, die das vorhandene organische Glasfasersubstrat nutzte, to achieve the kind of high wiring densities needed for thousands of signal paths. The company developed the new Infinity Fanout Link physical-layer, which uses a large number of 9.2 Gbps IF links with fanout wiring, to achieve 10x the wiring density between the GCD and an MCD, in comparison to the IFOP physical-layer used to connect a “Zen” processor CCD with the IOD. A fanout is a technique of achieving a large number of equal-length traces between two points, where putting them in straight lines isn’t possible. They are hence made to meander along obstacles (such as vias) in a manner that doesn’t compromise the equal trace-length needed to maintain signal integrity.
The only alternative to AMD for the Infinity Fabric Fanout wiring would have been to use a 3D packaging approach, durch Verwendung eines Silizium-Interposers (Ein Chip, der eine hochdichte mikroskopische Verdrahtung zwischen darauf gestapelten Chips ermöglicht). Die bisherigen MCM-GPUs von AMD verwendeten Interposer, um den GPU-Chip und die HBM-Stacks zu verbinden. Ein Interposer ist eine sehr teure Möglichkeit, eine Client-GPU zu bauen, mit Spielraum für zukünftige Preissenkungen, da es groß ist 55 nm-Klasse sterben von selbst, die so gestaltet ist, dass sie wie eine Leiterplatte wirkt.

Der offensichtliche Nachteil beim Zerfall eines monolithischen Logikchips ist die Latenz, was besonders für eine GPU kritisch ist. Das Unternehmen macht zwar keine Angaben dazu, Die Ausgliederung der Speichercontroller in MCDs hat eine hinzugefügt “bescheidene Menge” Latenz im Gegensatz zu einem On-Die-Vorgang (wie auf “Navi 21”). AMD gibt an, versucht zu haben, diese Latenz durch eine Erhöhung der Taktraten zu überwinden. Die Basis der Infinity Fabric-Uhr ist 43% höher als das auf der “Navi 21,” und die Spieluhren (Shader-Engine-Uhren) sind gestiegen 18% Gen-auf-Gen. Die kumulative Bandbreite der Infinity Fanout-Verbindungen zwischen den sechs MCDs und dem GCD, ist 5.4 TB/s. Diese Bandbreite wird benötigt, obwohl die gesamte GDDR6-Speicherbandbreite der GPU nur beträgt 960 GB/s (bei 20 Referenzspeichergeschwindigkeit in Gbit/s); denn die MCD enthält auch ein Segment des Infinity Cache, der mit einer viel höheren Datenrate arbeitet als der GDDR6-Speicher.
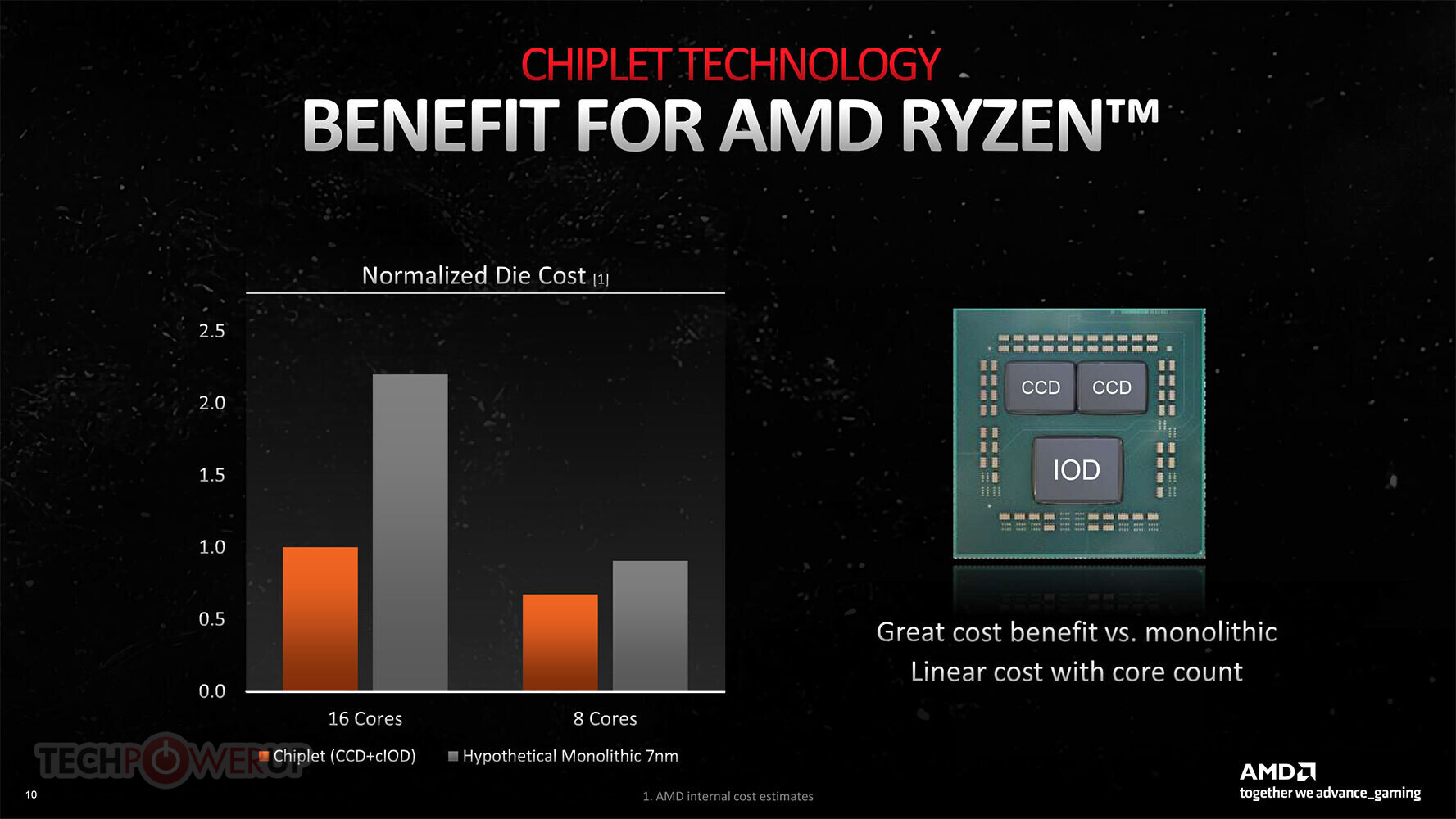

AMD hat es auch, erstmals, erläuterte die Wirtschaftlichkeit des Chiplet-Ansatzes beim Bau seiner Ryzen-Client-Prozessoren. Waren ein 16-Kern-Ryzen-Chip, wie der Ryzen 9 5950X, auf einem Monolithen gebaut worden 7 nm sterben, es hätte AMD gekostet 2.1 Mal mehr im Vergleich zu seinem Chiplet-basierten Ansatz, bei dem zwei 8-Kerne verwendet werden 80 mm² CCDs gepaart mit einem günstigeren 12 nm I/O-Chip. Denn dann hätte das Unternehmen viel größer bauen müssen 7 nm Chip mit allen 16 Kerne drauf, und die I/O-Komponenten; und es kommt auch zu geringeren Erträgen, da die resultierende Matrize größer ist (im Vergleich zu den winzigen CCDs).