










Intel Gaudi2 Accelerator schlägt NVIDIA H100 bei stabiler Diffusion 3 von 55%
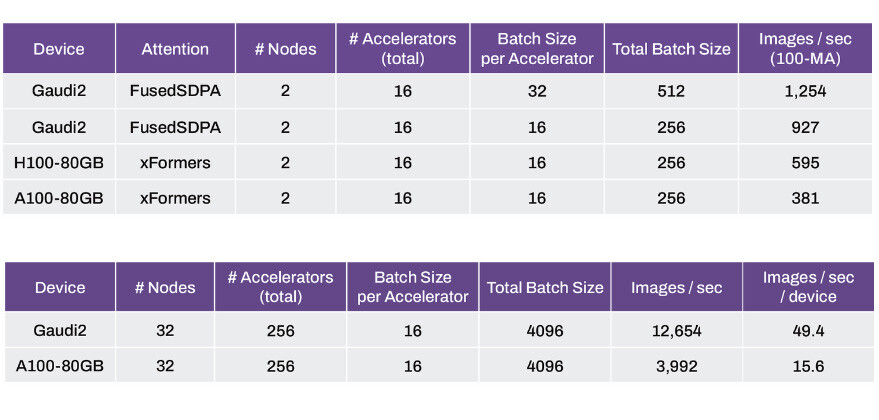
With 2 Knoten, 16 Beschleuniger, und eine konstante Chargengröße von 16 pro Beschleuniger (256 insgesamt), das Intel Gaudi2-Array erzeugen kann 927 Bilder pro Sekunde, compared to 595 Bilder für das H100-Array, und 381 Bilder pro Sekunde für das A100-Array, Halten Sie die Anzahl der Beschleuniger und Knoten konstant. Die Dinge noch einen Schritt weiter skalieren 32 Knoten, und 256 Beschleuniger oder einer Chargengröße von 16 pro Beschleuniger (Gesamtchargengröße von 4,096), Das Gaudi2-Array postet 12,654 Bilder pro Sekunde; oder 49.4 Bilder pro Sekunde und Gerät; compared to 3,992 Bilder pro Sekunde bzw 15.6 Bilder pro Sekunde und Gerät für die A100 der älteren Generation “Ampere” Array.

Diesbezüglich gibt es einen großen Vorbehalt, und das heißt, die Ergebnisse wurden mit der Basis-PyTorch erhalten; Stability AI gibt dies mit der TensorRT-Optimierung zu, A100-Chips erzeugen Bilder bis zu 40% schneller als Gaudi2. Dies wird durch weitere Optimierungen ergänzt, Der Gaudi2 sollte in der Lage sein, die Leistungsführerschaft zurückzuerobern. “Über Inferenztests mit der stabilen Diffusion 3 8B-Parametermodell bieten die Gaudi2-Chips eine ähnliche Inferenzgeschwindigkeit wie Nvidia A100-Chips mit Basis-PyTorch. Jedoch, mit TensorRT-Optimierung, Die A100-Chips erzeugen Bilder 40% schneller als Gaudi2. Das erwarten wir durch weitere Optimierungen, Gaudi2 wird bei diesem Modell bald den A100 übertreffen. In früheren Tests unseres SDXL-Modells mit Basis-PyTorch, Gaudi2 generiert eine 1024×1024 Bild in 30 tritt ein 3.2 Sekunden, versus 3.6 Sekunden für PyTorch auf A100s und 2.7 Sekunden für eine Generation mit TensorRT auf einem A100.” Stabilitäts-KI schreibt die schnellere und größere Verbindung zu 96 GB-Speicher machen die Intel-Chips konkurrenzfähig.
Stability AI plant die Implementierung von Gaudi2 in Stability Cloud.