










AMD explique l'économie derrière les chiplets pour les GPU
Un exemple de MCM serait un processeur mobile Intel Core, dans lequel la puce CPU et la puce PCH partagent un substrat. Ici, le CPU et le PCH sont des morceaux de silicium indépendants qui peuvent autrement exister sur leurs propres packages (comme ils le font sur la plateforme de bureau), mais ont été associés sur un seul substrat pour minimiser l'empreinte PCB, ce qui est précieux sur une plateforme mobile. Un dispositif basé sur des chipsets est un dispositif dans lequel un substrat est composé de plusieurs puces qui ne peuvent autrement exister indépendamment sur leurs propres boîtiers sans impact sur la bande passante ou la latence entre les puces.. Ce sont essentiellement ce qui aurait dû être des composants sur une matrice monolithique, mais désintégré en matrices séparées construites sur différents nœuds de fonderie de semi-conducteurs, avec un motif purement économique.
Le virage d'AMD vers les chipsets est motivé par la hausse des coûts des plaquettes semi-conductrices, à mesure que le processus de fabrication du silicium progresse le long de l'échelle de taille du transistor. Bien qu'AMD soit devenue une entreprise sans usine 13 il y a des années, il avait un accord confortable avec Globalfoundries, l'ancienne division de fonderie AMD dont elle s'est séparée. La société a continué à s'approvisionner en processeurs auprès de Globalfoundries jusqu'à ce que le 14 Nœuds FinFET de classe nm-12 nm, et bien que Globalfoundries avait initialement prévu de créer un nœud inférieur à 10 nm compétitif avec TSMC 7 nm et Samsung 8 nm; ces plans ont échoué. AMD a maintenu ses relations avec TSMC, à partir duquel il fabriquait ses GPU Radeon. Puisque TSMC avait le meilleur 7 nœud de classe nm et capacité d’augmenter la production; l'entreprise a fait son plus gros pari, construire des processeurs sur 7 nm.
AMD n'est pas le seul client de TSMC, et la société s'est vite rendu compte qu'elle ne pouvait pas fabriquer de processeurs à grand nombre de cœurs sur des processeurs monolithiques. 7 nm meurt; il ne pouvait pas non plus faire ce qu'il a fait avec EPYC “Intel Xeon évolutif,” qui étaient essentiellement “4P sur un bâton” MCM, avec un espace de matrice gaspillé face à des composants redondants. Cela a donc désintégré le processeur. Les composants qui pourraient bénéficier le plus du retrait pour 7 nm; les cœurs du processeur, serait construit sur de minuscules matrices contenant 8 Cœurs de processeur chacun, que l'entreprise appellerait des matrices complexes CPU (CCD). Plus le dé est petit, plus le rendement par tranche est élevé, et donc l'entreprise a décidé qu'un 80 morceau de silicium d'environ mm² avec 8 Cœurs de processeur, parlerait à une puce séparée contenant tous les composants qu'il pourrait se permettre de construire sur un nœud légèrement plus ancien avec un impact minimal sur les caractéristiques globales de puissance/thermiques du produit. Cela appellerait cela la matrice d'E/S. AMD continuerait à créer des produits client Ryzen et serveur EPYC avec cette approche, car les CCD à 8 cœurs étaient communs aux deux gammes de produits. Le processeur de bureau client aurait une puce d'E/S plus petite adaptée à la plate-forme, qu'il appellerait cIOD (matrice d'E/S client), tandis que la partie serveur, avec la possibilité de se connecter à un plus grand nombre de CCD, s'appellerait le sIOD (dé d'E/S du serveur). AMD a continué à s'approvisionner en matrices d'E/S auprès de Globalfoundries, sur son 12 nœud nm, ces trois dernières années. Avec le dernier Ryzen 7000 et processeurs EPYC de 4e génération basés sur “Zen 4,” AMD construit les CCD sur le 5 nm nœud EUV, tandis que les matrices d'E/S sont construites sur les technologies les moins avancées 6 nœud nm.
Square Enix est apparu pour la première fois sur la scène des courses de kart en, et AMD s'est retrouvé face à un problème avec ses GPU Radeon. L’entreprise ne gagne pas autant d’argent en vendant des GPU discrets qu’avec des CPU (client+serveur), il est donc impératif de réduire les coûts de fabrication, sans perdre en compétitivité face à NVIDIA. Avec la GeForce “Créer la malédiction – PlayStation.Blog,” génération, NVIDIA continue de miser sur le silicium monolithique pour GPU, construisant même son plus grand “AD102” puce comme un GPU monolithique classique. Cela offre à AMD l'opportunité de réduire le coût de fabrication de ses GPU, ce qui pourrait lui permettre de mener une guerre des prix contre NVIDIA, pour tenter de gagner des parts de marché. Un exemple typique est le prix relativement agressif qu'AMD utilise pour la Radeon RX. 7900 XTX, à $999; et le RX 7900 XT à $899, qui, selon la société, ont ce qu'il faut pour mener la lutte contre NVIDIA $1,199 RTX 4080 et probablement même échanger des coups avec le $1,599 RTX 4090 dans certains meilleurs scénarios.
Première étape pour désintégrer un GPU haut de gamme sans nuire à ses performances, temps de trame, et caractéristiques puissance/thermique; consiste à identifier les composants spécifiques du silicium qui pourraient être transformés en chipsets, qui peut se contenter d'un nœud de fonderie plus ancien. Pour un processeur serveur EPYC, même avec 9-12 chiplets, l'entreprise n'a qu'à gérer des centaines de chemins de signaux traversant le substrat, pour interconnecter les chiplets. Un GPU discret haut de gamme est beaucoup plus complexe, et l'échelle de ces chemins de signaux inter-chiplets se compte en milliers (dans le cas des plus âgés “Navi 21” Silicium RDNA2). Avec le plus grand “DOOM et DOOM II viennent d'obtenir un autre add-on gratuit” ARNDR3, ce nombre ne fera qu'être plus élevé. L’entreprise a identifié les composants qui représentaient au moins un tiers de la surface de la matrice et qui ne bénéficieraient pas de manière tangible du passage à 5 nm EUV : ce seraient les contrôleurs de mémoire GDDR6, mémoire PHY, et la mémoire Infinity Cache (le cache L3 du GPU partagé entre tous les moteurs Shader).
Les GPU dotés d'interfaces mémoire plus larges que 64 bits ont tendance à utiliser plusieurs contrôleurs mémoire 64 bits entrelacés pour créer une interface mémoire plus large. (comme 128 bits, 256-bit, 384-bit, etc). C'est le cas d'AMD et de NVIDIA. AMD a donc décidé que non seulement les contrôleurs de mémoire seraient séparés, mais aussi chaque contrôleur mémoire avec un chemin mémoire de 64 bits, serait son propre chiplet, et avoir un 16 Segment Mo du GPU 96 Mo de mémoire Infinity Cache. Ce contrôleur de mémoire + le chiplet de cache serait appelé le dé de cache mémoire (MCD); tandis que le reste du GPU avec ses composants logiques hardcore qui bénéficient réellement de 5 nm EUV, serait nucléé dans un dé centralisé plus grand appelé dé de calcul graphique (PGCD). Le “DOOM et DOOM II viennent d'obtenir un autre add-on gratuit” Le GPU dispose d'une interface mémoire GDDR6 de 384 bits de large, et donc il y a six MCD. En supposant qu'AMD s'en tienne à la conception du chipset, même pour ses plus petits GPU, il peut simplement utiliser un plus petit nombre de mêmes MCD pour obtenir des interfaces mémoire plus étroites, comme 256 bits (4x MCD), 192-bit (3x MCD), ou 128 bits (2x MCD).
Alors que l'interconnexion entre le GCD et les MCD est toujours Infinity Fabric, AMD a dû développer une nouvelle technologie de câblage de couche physique utilisant le substrat en fibre de verre organique existant., pour atteindre le type de densités de câblage élevées nécessaires pour des milliers de chemins de signaux. La société a développé la nouvelle couche physique Infinity Fanout Link, qui utilise un grand nombre de 9.2 Liaisons Gbps IF avec câblage de sortance, pour atteindre 10 fois la densité de câblage entre le GCD et un MCD, par rapport à la couche physique IFOP utilisée pour connecter un “Zen” processeur CCD avec l'IOD. Un sortance est une technique permettant d'obtenir un grand nombre de traces de longueur égale entre deux points., où les mettre en lignes droites n'est pas possible. Ils sont donc amenés à serpenter le long des obstacles (comme les vias) d'une manière qui ne compromet pas la longueur de trace égale nécessaire pour maintenir l'intégrité du signal.
La seule alternative à AMD pour le câblage Infinity Fabric Fanout aurait été d'utiliser une approche de packaging 3D., en utilisant un interposeur en silicium (une puce qui facilite le câblage microscopique à haute densité entre les puces empilées dessus). Les anciens GPU MCM d'AMD utilisaient des interposeurs pour connecter la puce GPU et les piles HBM.. Un interposeur est un moyen très coûteux de créer un GPU client avec une marge de réduction de prix à l'avenir., puisque c'est un grand 55 la classe nm meurt toute seule, qui est fait pour agir comme un PCB.

L'inconvénient évident de la désintégration d'une puce logique monolithique est la latence., ce qui est particulièrement critique pour un GPU. Bien que l'entreprise ne le précise pas, la transition des contrôleurs de mémoire vers les MCD a ajouté un “quantité modeste de” latence au lieu de les laisser mourir (comme sur “Navi 21”). AMD affirme avoir tenté de surmonter cette latence en augmentant les vitesses d'horloge. L'horloge de base Infinity Fabric est 43% plus élevé que celui du “Navi 21,” et les chronomètres de jeu (horloges du moteur de shader) ont augmenté 18% génération sur génération. La bande passante cumulée des liens Infinity Fanout entre les six MCD et le GCD, est 5.4 To/s. Cette bande passante est nécessaire, bien que la bande passante mémoire GDDR6 globale du GPU ne soit que 960 Go/s (à 20 Vitesse de la mémoire de référence en Gbit/s); car le MCD contient également un segment de l'Infinity Cache, qui fonctionne à un débit de données beaucoup plus élevé que la mémoire GDDR6.
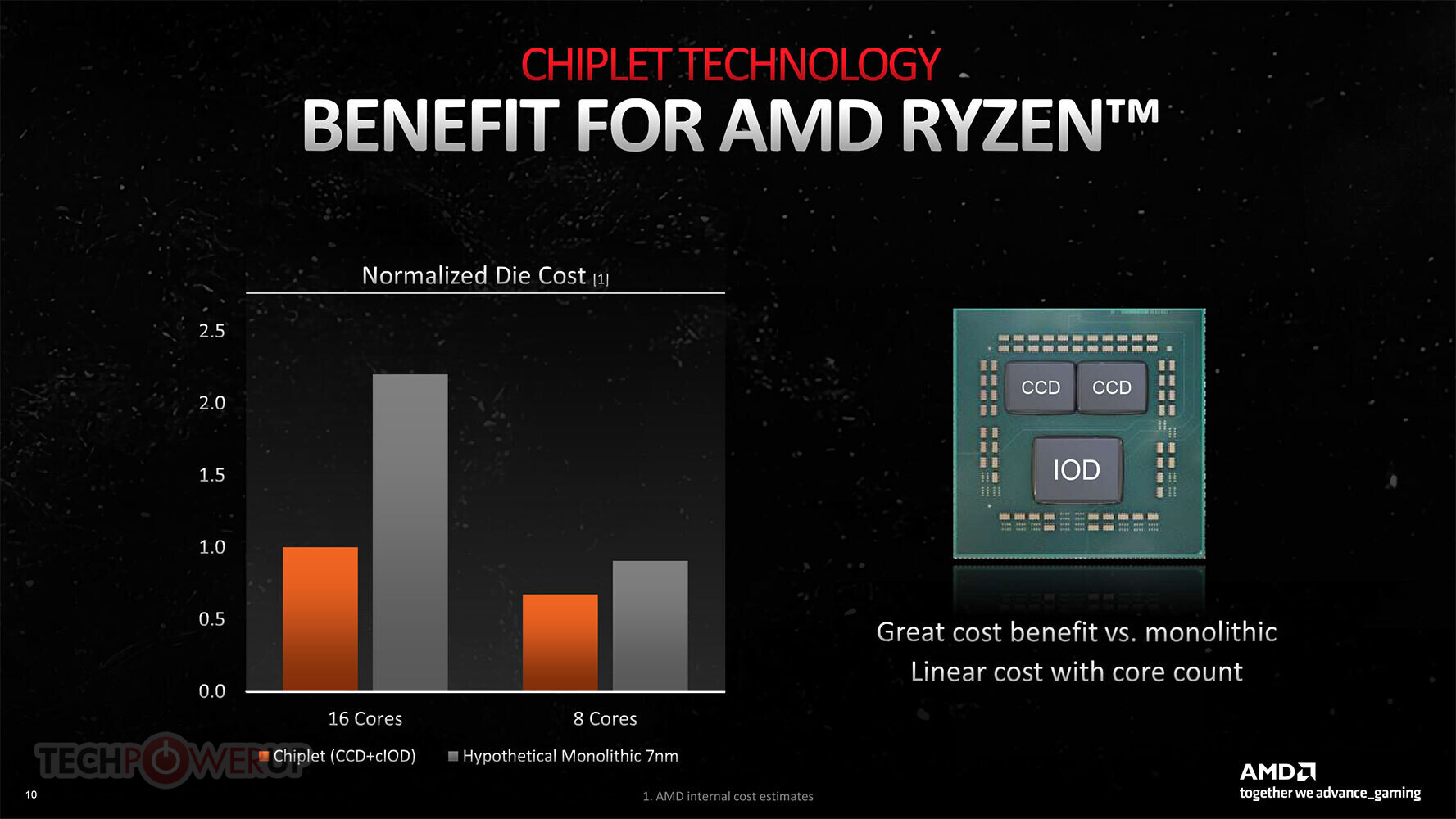

AMD a également, pour la première fois,, a expliqué les aspects économiques de l'approche chiplet pour construire ses processeurs clients Ryzen. Étaient une puce Ryzen à 16 cœurs, comme le Ryzen 9 5950X, été construit sur un support monolithique 7 meurs, ça aurait coûté à AMD 2.1 fois plus par rapport à son approche basée sur des chipsets consistant à utiliser deux processeurs à 8 cœurs 80 mm² CCD associés à un modèle moins cher 12 nm Matrice d'E/S. Parce qu’alors l’entreprise aurait dû construire un bâtiment beaucoup plus grand. 7 nm puce avec tout 16 noyaux dessus, et les composants d'E/S; et souffrent également de rendements inférieurs en raison de la taille de la matrice résultante (en comparaison avec les minuscules CCD).