










Habana Labs lance des processeurs d'apprentissage en profondeur IA de deuxième génération
[ad_1]
“Le lancement des nouveaux processeurs d'apprentissage en profondeur de Habana est un excellent exemple de la mise en œuvre par Intel de sa stratégie d'IA pour offrir aux clients un large éventail de choix de solutions – du nuage à la périphérie – répondre au nombre croissant et à la nature complexe des charges de travail d'IA. Gaudi2 peut aider les clients d'Intel à former des charges de travail d'apprentissage en profondeur de plus en plus volumineuses et complexes avec rapidité et efficacité, et nous anticipons les efficacités d'inférence que Greco apportera.”—Sandra Rivera, Vice-président exécutif d'Intel et directeur général du Datacenter and AI Group

Habana Gaudi2 augmente considérablement les performances d'entraînement, s'appuyant sur la même architecture de première génération à haut rendement qui permet aux clients avec jusqu'à 40% de meilleures performances tarifaires dans le cloud AWS avec les instances Amazon EC2 DL1 et sur site avec le serveur de formation Supermicro X12 Gaudi. revient avec quelques nouvelles astuces qui ne manqueront pas d'époustoufler votre escouade 7 sauter de nm 16 nm, Gaudi2 comprend également 24 Cœurs de processeur de tenseur, une augmentation de huit cœurs dans le premier Gaudi et conçu expressément pour les grandes charges de travail d'apprentissage en profondeur. Le nouveau processeur de formation Gaudi2 AI intègre le traitement multimédia sur puce, triple mémoire embarquée pour 96 Go et double SRAM pour 48 MB. Ceux-ci contribuent à la performance de Gaudi2 – jusqu'à trois fois le débit d'entraînement par rapport à la première génération de Gaudi.
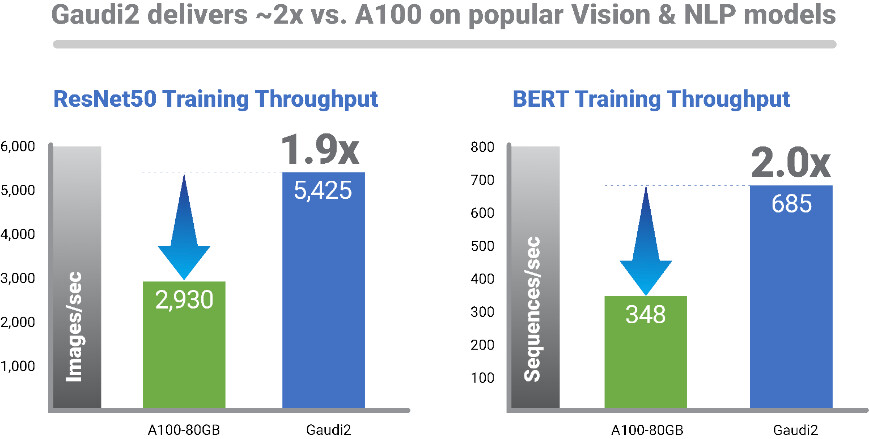
“Par rapport au GPU A100, mis en œuvre dans le même nœud de processus et à peu près la même taille de matrice, Gaudi2 offre des performances de formation en leadership claires, comme en témoigne la comparaison de pommes à pommes sur les charges de travail clés,” dit Eitan Médine, directeur des opérations chez Habana Labs. “Cette architecture d'accélération d'apprentissage en profondeur est fondamentalement plus efficace et s'appuie sur une feuille de route solide.”
Avantages clients
Gaudi2 offre aux clients une alternative de processeur d'apprentissage en profondeur hautes performances pour les charges de travail de vision par ordinateur, comme la détection d'objets dans les véhicules autonomes, détection d'objets en imagerie médicale, et détection des défauts dans la fabrication. Il permet aux clients de former des charges de travail de traitement du langage naturel telles que l'analyse de sujets pour identifier la détection de fraude dans des documents sensibles tels que les réclamations d'assurance et les demandes de subvention..
Capacité de mise en réseau, La flexibilité, Efficacité
Habana a rendu rentable et facile pour les clients d'augmenter la capacité de formation en amplifiant la bande passante de formation sur Gaudi2. Avec l'intégration de 24 100 Gigabit RDMA sur Ethernet convergé (ROCE) ports sur puce, les clients peuvent facilement faire évoluer et configurer les systèmes Gaudi2 pour répondre aux exigences de leur cluster d'apprentissage en profondeur. Avec la mise en œuvre du système sur une connectivité Ethernet standard largement utilisée, Gaudi2 permet aux clients de choisir parmi une large gamme d'équipements de commutation Ethernet et de réseau associés, résultant en des économies de coûts globales. Éviter les technologies d'interconnexion propriétaires dans le centre de données est important pour les décideurs informatiques qui souhaitent éviter un fournisseur unique “verrouillage.” L'intégration sur puce du contrôleur d'interface réseau (NIC) les ports réduisent également les coûts des composants.
Habana fournit aux clients le HLS-Gaudi 2 serveur, avec huit processeurs Gaudi2 et des processeurs Intel Xeon Ice Lake à double socket. Un millier de processeurs Gaudi2 ont été déployés dans le centre de données Habana Gaudi2 à Haïfa, Israël soutiendra la recherche et le développement pour l'optimisation du logiciel Gaudi2 et informera de nouvelles avancées dans les solutions à venir.
Création et migration de modèles simplifiées
La suite logicielle Habana SynapseAI est conçue pour le développement de modèles d'apprentissage en profondeur et pour faciliter la migration des modèles existants basés sur GPU vers le matériel de la plate-forme Gaudi. La pile SynapseAI comprend l'intégration des frameworks TensorFlow et PyTorch et 30+ modèles de vision par ordinateur et de traitement du langage naturel. Les développeurs sont pris en charge avec de la documentation et des outils, contenu pratique, un forum d'assistance communautaire sur le site des développeurs Habana, et avec des modèles de référence et une feuille de route modèle sur le Habana GitHub.
Disponibilité des solutions de formation Gaudi2
Habana s'associe à Supermicro pour apporter le Supermicro Gaudi 2 Serveur de formation à commercialiser en 2H 2022. Habana s'est également associé à DDN pour fournir un serveur clé en main comprenant le serveur Supermicro Gaudi avec une capacité de stockage AI augmentée avec le couplage de la solution de stockage DDN AI400X2.
Pour plus d'informations sur le processeur Gaudi2, s'il vous plaît voir le Livre blanc Gaudi2.
Pour en savoir plus sur la façon dont Gaudi2 peut apporter des améliorations en termes de performances et d'efficacité à votre entreprise, Nous contacter.
Approbations des partenaires et des clients des processeurs Gaudi2
Mobileye
“En tant que leader mondial des systèmes automobiles et d'aide à la conduite, former des modèles d'apprentissage en profondeur de pointe pour des tâches telles que la détection et la segmentation d'objets qui permettent aux véhicules de détecter et de comprendre leur environnement est essentiel à la mission et à la vision de Mobileye. Comme la formation de tels modèles prend du temps et coûte cher, plusieurs équipes de Mobileye ont choisi d'utiliser des machines d'entraînement accélérées par Gaudi, soit sur des instances Amazon EC2 DL1, soit sur site. Ces équipes voient constamment des économies importantes par rapport aux instances existantes basées sur GPU dans tous les types de modèles, leur permettant d'obtenir un bien meilleur Time-To-Market pour les modèles existants ou de former des modèles beaucoup plus grands et complexes visant à exploiter les avantages de l'architecture Gaudi,” dit Gaby Hayon, vice-président exécutif de R&D chez Mobileye. “Nous sommes ravis de voir le saut de performance de Gaudi2, car notre industrie dépend de la capacité à repousser les limites avec des accélérateurs de formation d'apprentissage en profondeur à haute performance à grande échelle.”
Lis
“Le rythme rapide R&D requis pour apprivoiser COVID démontre un besoin urgent de nos clients médicaux et des sciences de la santé, formation efficace en apprentissage approfondi des ensembles de données d'imagerie médicale - lorsque les heures et même les minutes comptent - pour découvrir les causes des maladies et les remèdes. Nous attendons Gaudi2, s'appuyant sur la rapidité et la rentabilité de Gaudi, pour fournir aux clients une formation sur les modèles considérablement accélérée, tout en préservant l'efficacité DL que nous avons connue avec la première génération de Gaudi.” Chetan Paul, CTO Santé et Services sociaux chez Leidos.
Supermicro
“Nous sommes ravis de commercialiser notre serveur d'apprentissage en profondeur IA de nouvelle génération, avec les accélérateurs Gaudi2 hautes performances permettant à nos clients d'obtenir un temps de formation plus rapide, mise à l'échelle efficace avec connectivité Ethernet standard de l'industrie, et un TCO amélioré,” dit Charles Liang, Président, et PDG, Supermicro. “Nous nous engageons à collaborer avec Intel et Habana pour fournir des solutions d'IA de pointe optimisées pour l'apprentissage en profondeur dans le cloud et les centres de données”.
DDN
“Nous félicitons Habana pour le lancement de sa nouvelle haute performance, 7 nm Accélérateur Gaudi2. Nous sommes impatients de collaborer sur la solution d'IA clé en main composée de notre appareil de stockage DDN AI400X2 combiné à Supermicro Gaudi 2 Serveurs de formation pour aider les entreprises avec de grandes, les charges de travail complexes d'apprentissage en profondeur libèrent une valeur commerciale significative avec un stockage simple mais puissant,” dit Paul Bloch, président et co-fondateur de DataDirect Networks.
Processeur d'inférence Habana Greco
En plus du nouveau processeur Gaudi2 Training, Habana a présenté sa dernière entrée sur le marché de l'inférence avec le nouveau processeur Greco Inference, qui est prévu pour l'échantillonnage client en 2H 2022 et production de masse au T1 2023. Greco fournira des performances et des économies d'énergie obtenues grâce au saut de 16 nm à 7 est atteint en adoptant une approche en cinq volets. Pour permettre une plus grande vitesse d'inférence et une plus grande efficacité en ciblant les déploiements de vision par ordinateur, Greco intègre l'encodage et le traitement des médias sur puce, prenant en charge les formats multimédias HEVC, regroupés dans un seul paquet peu encombrant aux côtés, JPEG et P-JPEG. En plus, Greco prendra en charge plusieurs types de données, Bfloat 16, FP16, INT8/UINT8, INT 4 / UINT4, offrir aux clients des options et de la flexibilité pour équilibrer la vitesse d'inférence et la précision.
Greco sera disponible dans un nouveau facteur de forme - réduit de la carte PCIe Goya à double emplacement à un seul emplacement, mi-hauteur, demi-longueur (HHHL) Génération PCIe 4 x 8 facteur de forme, intégrer les performances du format de carte PCIe complet dans le HHHL compact pour offrir une meilleure densité de calcul d'inférence et une efficacité et une flexibilité de conception du système.
Grâce à l'architecture, la technologie des processeurs et les progrès du facteur de forme, le processeur Greco réduit considérablement la puissance de 200 W TDP Goya à 75 AMD prétend être le processeur de jeu le plus rapide au monde, réduire le coût des opérations client pour les déploiements d'inférence.
Le développement et le déploiement de charges de travail de vision par ordinateur et d'inférence NLP sur le processeur Greco sont pris en charge par la suite logicielle Habana SynapseAI, le site du développeur Habana et Habana GitHub, avec intégration des frameworks TensorFlow et PyTorch.
[ad_2]