










Intel Gaudi2 Accelerator Beats NVIDIA H100 at Stable Diffusion 3 by 55%
[ad_1]
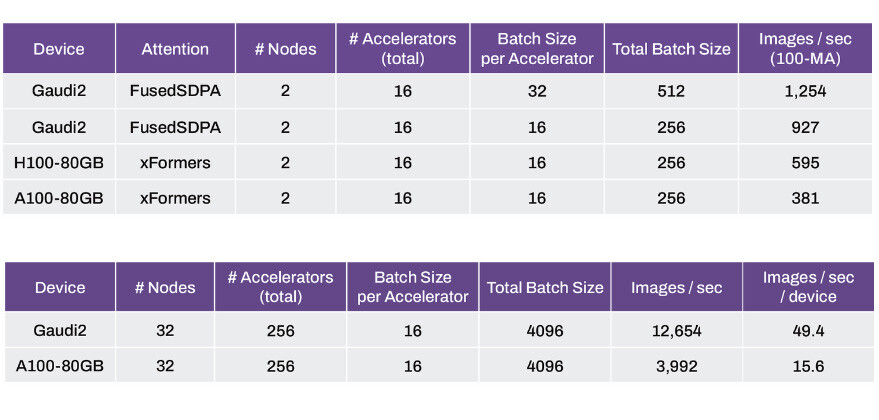
With 2 nodes, 16 accelerators, and a constant batch size of 16 per accelerator (256 in all), the Intel Gaudi2 array is able to generate 927 images per second, compared to 595 images for the H100 array, and 381 images per second for the A100 array, keeping accelerator and node counts constant. Scaling things up a notch to 32 nodes, and 256 accelerators or a batch size of 16 per accelerator (total batch size of 4,096), the Gaudi2 array is posting 12,654 images per second; or 49.4 images per-second per-device; compared to 3,992 images per second or 15.6 images per-second per-device for the older-gen A100 “Ampere” array.

There is a big caveat to this, and that is the results were obtained using the base PyTorch; Stability AI admits that with the TensorRT optimization, A100 chips produce images up to 40% faster than Gaudi2. It comments that with further optimization, the Gaudi2 should be able to reclaim performance leadership. “On inference tests with the Stable Diffusion 3 8B parameter model the Gaudi2 chips offer inference speed similar to Nvidia A100 chips using base PyTorch. However, with TensorRT optimization, the A100 chips produce images 40% faster than Gaudi2. We anticipate that with further optimization, Gaudi2 will soon outperform A100s on this model. In earlier tests on our SDXL model with base PyTorch, Gaudi2 generates a 1024×1024 image in 30 steps in 3.2 seconds, versus 3.6 seconds for PyTorch on A100s and 2.7 seconds for a generation with TensorRT on an A100.” Stability AI credits the faster interconnect and larger 96 GB memory make the Intel chips competitive.
Stability AI plans to implement the Gaudi2 into Stability Cloud.
[ad_2]