










Intel rilascia OpenVINO 2022.1 Intel rilascia OpenVINO
[ad_1]
“The latest release of OpenVINO 2022.1 builds on more than three years of learnings from hundreds of thousands of developers to simplify and automate optimizations. The latest upgrade adds hardware auto-discovery and automatic optimization, so software developers can achieve optimal performance on every platform. This software plus Intel silicon enables a significant AI ROI advantage and is deployed easily into the Intel-based solutions in your network,” said Adam Burns, vicepresidente, OpenVINO Developer Tools in the Network and Edge Group.
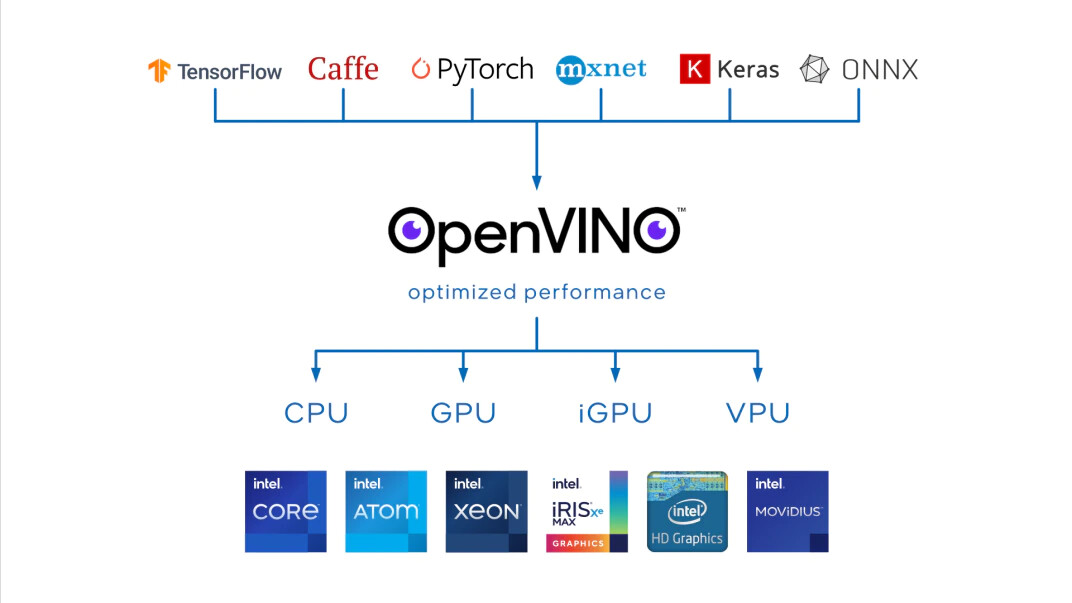
The Intel Distribution of OpenVINO toolkit – built on the foundation of oneAPI – is a tool suite for high-performance deep learning, targeted at faster, more accurate real-world results deployed into production across diverse Intel platforms from edge to cloud. OpenVINO enables high-performing applications and algorithms to be deployed in the real world with a streamlined development workflow.
Edge AI is changing every market, enabling new and enhanced use cases across industries from manufacturing and health and life sciences applications to retail, safety and security. According to research from Omdia, global edge AI chipset revenue will reach $51.9 miliardi di 2025, driven by the increasing need for AI inference at the edge. Edge inference reduces latency and bandwidth and improves performance to meet the increasingly time-critical processing demands of emerging Internet of Things (IoT) devices and applications.
In parallelo, sviluppatori’ workloads are ever-increasing and changing. As a result, they are calling for simpler, more automated processes and tools with smart, comprehensive capabilities for optimized performance from build to deployment.
New features make it simpler for developers to adopt, maintain, optimize and deploy code with ease across an expanded range of deep learning models. I punti salienti includono:
aggiornato, API più pulita
- Meno modifiche al codice durante la transizione dai framework: I formati di precisione sono ora preservati con meno casting, e i modelli non necessitano più di conversione del layout.
- Un percorso più semplice verso un'IA più veloce: I parametri API di Model Optimizer sono stati ridotti per ridurre al minimo la complessità.
- Allenati tenendo presente l'inferenza: Estensioni di formazione OpenVINO e framework di compressione della rete neurale (NNCF) offrire modelli di addestramento del modello opzionali che forniscono ulteriori miglioramenti delle prestazioni con precisione preservata per il riconoscimento dell'azione, classificazione delle immagini, riconoscimento vocale, risposta alle domande e traduzione.
Supporto di modelli più ampio
- Supporto più ampio per modelli di programmazione in linguaggio naturale e casi d'uso come la sintesi vocale e il riconoscimento vocale: Le forme dinamiche supportano meglio i trasformatori della famiglia BERT e Hugging Face.
- Ottimizzazione e supporto per la visione artificiale avanzata: La famiglia Mask R-CNN è ora più ottimizzata e doppia precisione (FP64) è stato introdotto il supporto del modello.
- Supporto diretto per i modelli PaddlePaddle: Model Optimizer ora può importare direttamente i modelli PaddlePaddle senza prima convertirli in un altro framework.
Portabilità e prestazioni
- Utilizzo più intelligente del dispositivo senza modificare il codice: La modalità dispositivo AUTO rileva automaticamente la capacità di inferenza del sistema disponibile in base ai requisiti del modello, quindi le applicazioni non hanno più bisogno di conoscere in anticipo il proprio ambiente di elaborazione.
- Ottimizzazione esperta integrata nel toolkit: Attraverso la funzionalità di dosaggio automatico, le prestazioni del dispositivo aumentano, ottimizzare e personalizzare automaticamente le impostazioni di throughput appropriate per gli sviluppatori’ configurazione del sistema e modello di deep learning. Il risultato è un parallelismo scalabile e un utilizzo ottimizzato della memoria.
- Costruito per Intel Core di 12a generazione : Supporta l'architettura ibrida per offrire miglioramenti per l'inferenza ad alte prestazioni su CPU e GPU integrate.
[ad_2]